
Regression and Time Series Prediction: Training and Testing
Published:
Regression and Time Series Prediction: Training and Testing
As we’ve noticed in power flow problems we’ve been looking at in class, grid operators are brutally constrained by the physics of electricity. Chief amongst these: the power supplied to the network need to equal the demand at each moment in time. Scheduling production amongst many power generators is a non-trivial task since they are expensive to start and run and the generation schedule needs to be adaptable to rapid fluctuations in demand. This problem is known as generator dispatch: a grid operator wants to minimize the cost of generating electricity while ensuring enough power is being generated in reserve because of unexpected increases in demand or failures in the grid.
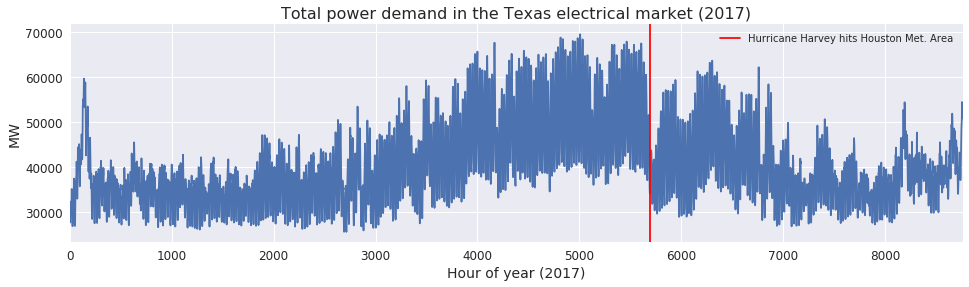
Fig. 1 illustrates the total power demand in the Texas electrical market (ERCOT) in 2017. Recall Hurricane Harvey caused massive flooding in Houston in late August that year; the red line in Fig. 1 marks 24 hours prior to Hurricane Harvey hitting Houston and causing widespread outages in one of the largest cities in Texas.
The first step in setting the generation schedule is predicting how much power will be consumed by the grid at future time steps. We’re going to suppose that our job is to predict how much power the grid will consume in the next hour for a given day. We’ll suppose that for a typical day, each hour can be predicted as a function of the previous hour’s power consumption and a number of other features, like temperature, humidity, time of day, etc. Let $\boldsymbol{x}_{t} = \langle x_{i,t} \rangle$ where each vector component $i$ is one of these data features at time $t$, and $\boldsymbol{p}_{t+1}$ is the power consumed at time $t + 1$. If this function is linear, then,
where $w$ is the vector of weights we would solve for in the standard linear regression problem. From the slides, this is an autoregressive model of order 1, meaning the next time step only depends on the previous. Including previous historical values (i.e. $x_{t-1}, x_{t-2}\ldots$) increases the order:
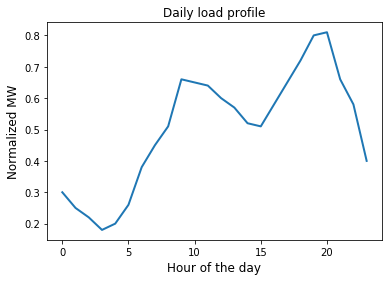
This load profile is representative of how much power might be consumed over the course of a day. This is a typical profile for many grids, with a small peak in the morning and a larger peak in the evening, with the least power demanded in the earliest hours of the morning. Unfortunately a linear model won’t describe the behavior we see here, so we’ll assume we need to use a polynomial basis in this and the following assignments. We’ll need pass the input data through a polynomial basis function $\phi$, just like we have in the previous assignments:
For this assignment we’ll use a polynomial basis function, noting that each sample needs to be passed through it’s own basis function, learn the weights $w_{i}$ on a training data set, and test the model on a testing data set.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
#we'll use these helper functions to generate a polynomial basis on the feature data matrices X
def poly_basis_single_sample(x, k):
#this function will help us quickly generate a polynomial basis
#k is the largest polynomial degree the basis runs to
out = []
for i in range(k+1):
#notice that first value of i will be 0, so the bias term is included
out.append(np.power(x, i))
return(np.asarray(out))
#this one is not required for this assignment but can be used; we will use in the next assignment
def poly_basis_multi_sample(X, k):
out = []
for sample_row in range(X.shape[0]):
sample = X[sample_row]
#poly basis returns an m feature x k power matrix, we need to vectorize it by using .flatten()
poly = np.asarray(poly_basis_single_sample(sample, k)).flatten()
out.append(poly)
return(np.asarray(out))
#import the training data
data = np.loadtxt("homework_4_data_ex_train.txt")
#in this example there are 5 feature dimensions over 24 hours
X_train_raw = data[:,0:4]
#in order to use 2 hours at a time, we need to pair two hour rows together, one hour at a time, passing each
#hour sample through the polynomial basis function with a chosen degree:
poly_degree = 3
X_train = []
for i in range(24 - 2): #24 hours minus the order
#get the individual sample for each time step you need, pass it through the polynomial basis function, vectorize
t_0 = poly_basis_single_sample(X_train_raw[i,:], poly_degree).flatten()
t_1 = poly_basis_single_sample(X_train_raw[i+1,:], poly_degree).flatten()
X_train.append(np.concatenate((t_0, t_1)))
X_train = np.asarray(X_train)
#the last column is the output p_{t+1} we need to learn
#in order to save the data file, the Y column is 0-padded in the first two values, so we start from the third element
Y_train = data[:,5][2:]
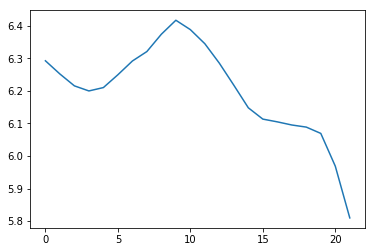
plt.plot(Y_train)
plt.show()
#notice Y_train is only 22 hours long, since the model we'll train in the example is order two, we need the first
#and second hour of the day in order to predict the third hour, otherwise we'd need additional data from the
#previous day; to keep things simple we'll restrict ourselves to 24 hour windows
print(X_train.shape)
print(Y_train.shape)
(22, 32)
(22,)
#similarly we'll load the test data
#import the training data
data_test = np.loadtxt("homework_4_data_ex_test.txt")
X_test_raw = data_test[:,0:4]
poly_degree = 3
X_test = []
for i in range(24 - 2):
t_0 = poly_basis_single_sample(X_test_raw[i,:], poly_degree).flatten()
t_1 = poly_basis_single_sample(X_test_raw[i+1,:], poly_degree).flatten()
X_test.append(np.concatenate((t_0, t_1)))
X_test = np.asarray(X_test)
Y_test = data_test[:,5][2:]
Now we’ll use LASSO to fit a polynomial basis to a time series model of order 2, and polynomial basis with degree 3
lasso_regressor = linear_model.Lasso(alpha=0.001, fit_intercept=False, tol=0.01, max_iter=10000)
#this fits the outputs Y to the polynomial basis of inputs in the range -2 to 2
lasso_regressor.fit(X_train, Y_train)
#these are the weights the model learns
w = lasso_regressor.coef_
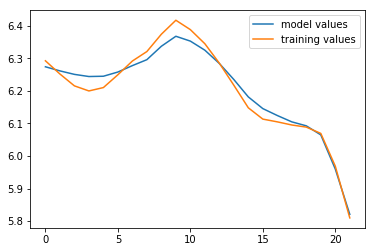
#here we plot our training data, model, and test data. Notice the model and training data are relatively close
#but the true values are a little farther away. Both the train and test sets were generated with the same weights
#we'll try to figure out what's going on in this and next assignment
plt.plot(X_train.dot(w), label="model values") #our model
plt.plot(Y_train, label="training values") #our training data
plt.legend()
plt.show()
Problem 1
In the above example we’ve split our data into a train and test set. Use the model $w$ we learned on the test data. X_test is reformatted so that each row is full sample, $x_{t}$ and $x_{t-1}$ How does the model perform on the test data? Plot the test data, the model predictions, and the MAE (mean absolute error).
#insert your code here
Problem 2
We’re going to look at what happens when we overfit a model.
Pass the training and test data through the basis function as above. Train a model $w$ with the training set using LASSO and the parameters given below. In one plot, plot the model applied to the training data and training output values. In another plot, draw the model on the test data and test output values. In your own words, describe what happens.
#use these parameters for LASSO and the polynomial basis function
poly_degree = 9 #higher than our previous problem
alpha = 0.000001 #much smaller than our previous problem
data_train = np.loadtxt("homework_3_data_ex_train.txt")
X_train_raw_prob_2 = data_train[:,0:4]
Y_train_raw_prob_2 = data_train[:,5][2:]
data_test = np.loadtxt("homework_3_data_ex_test.txt")
X_test_raw_prob_2 = data_test[:,0:4]
Y_test_raw_prob_2 = data_test[:,5][2:]
#pass each set data set X through the basis function above with the appropriate polynomial degree
#insert code here
Problem 3
Now we’re going to overfit in another way. We’re going to increase the order of the model. We happen to know that the true data was generated with an autoregressive equation of order 3. Suppose we didn’t know, and we guessed much higher without doing any sort of auto-correlation tests.
Train a model of order 7. You’ll only have 24 - 7 values to predict, since you need the first 7 values of x to predict the first y. Adjust the for-loop in problem 1 to include 7 consecutive values, instead of 2. Just like problem 2, do one plot with the model on the training data and training output values, and a second plot with the model on the test data and the test output values.
#use these parameters for LASSO and the polynomial basis function
poly_degree = 3
alpha = 0.001
data_train = np.loadtxt("homework_3_data_ex_train.txt")
X_train_raw_prob_3 = data_train[:,0:4]
Y_train_raw_prob_3 = data_train[:,5][7:] #we're picking up y from 7 onwards
data_test = np.loadtxt("homework_3_data_ex_test.txt")
X_test_raw_prob_3 = data_test[:,0:4]
Y_test_raw_prob_3 = data_test[:,5][7:]
#pass each set data set X through the basis function above with the appropriate polynomial degree
#insert code here
Bonus Problem
Use a Fourier basis (sines and cosines) either in conjunction with a polynomial basis, or on its own, to create a forecast model similar to polynomial basis with an auto-regressive model order 2. Hint: you can use the gradient descent method from homework 1, but you need to incoporate a weight inside of the Fourier terms in addition to the outside; that means you need to compute an extra partial derivative with respect to the loss for each additional weight term.
#insert your code here